Code is truth, but architecture is strategy.
For the past two weeks, I’ve been deep in the codebase of AMODX, building the core blocks (Hero, Pricing, Contact) and wiring up the Model Context Protocol (MCP) so I can chat directly with my database.
But sometimes, you have to zoom out to see why you are building.
I realized that explaining “Serverless” to agency owners is a losing battle. They don’t care about Lambda. They care about Risk and Speed.
So I mapped out the fundamental difference between the “Old World” (WordPress) and the “New World” (AMODX).
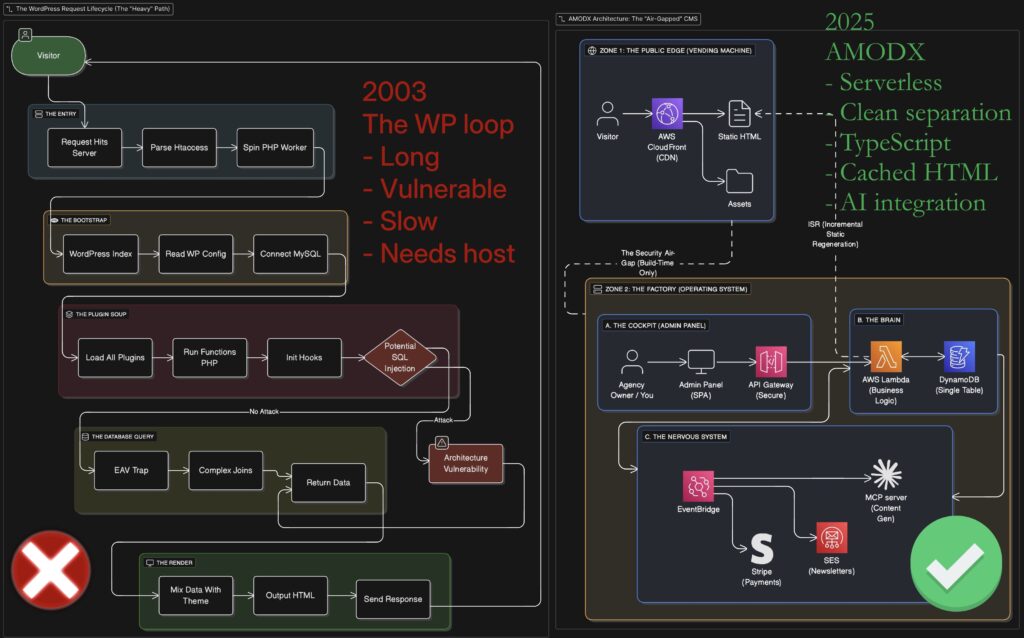
The Problem: The Monolith Tangle
When you host a WordPress site, the “Factory” (PHP/MySQL) is also the “Storefront.” Every visitor walks right into the factory floor.
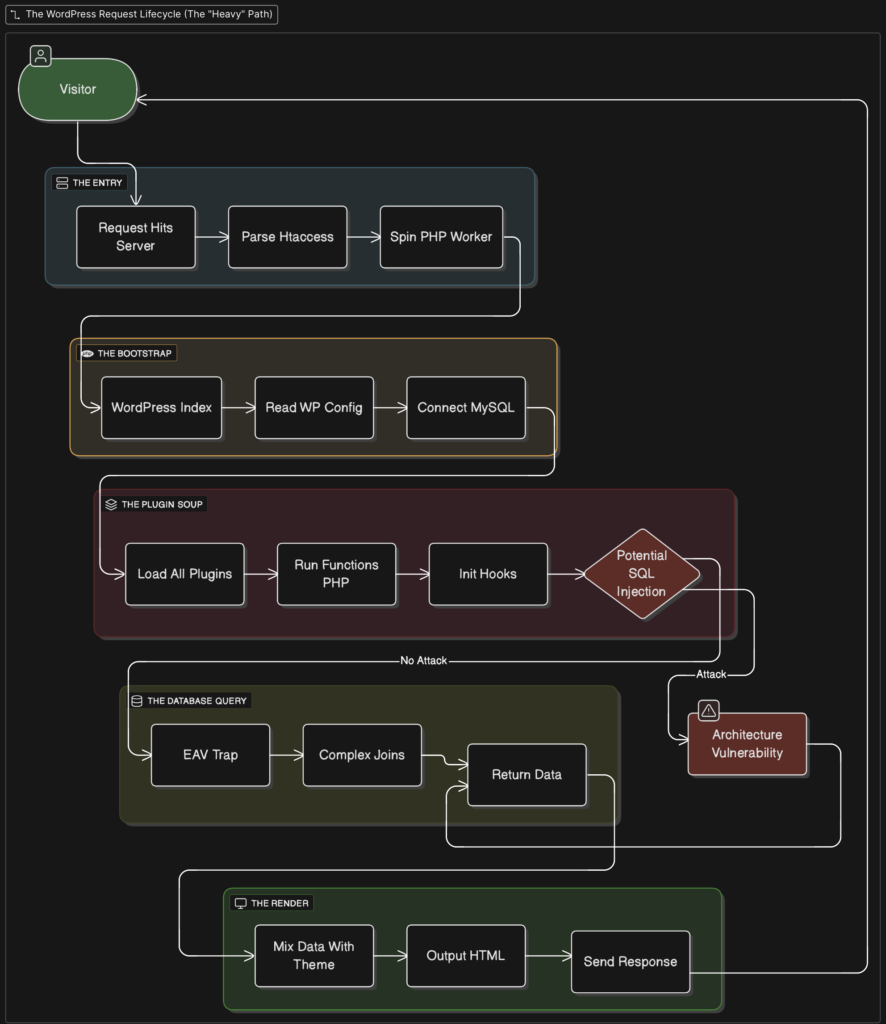
If a plugin breaks in the factory, the storefront crashes. If a hacker finds a door in a plugin, they are inside the database. It is a vertical stack of dependencies where Latency and Vulnerability compound.
The Solution: The AMODX “Air-Gap”
AMODX is different. It uses an Air-Gapped Architecture.
We separate the Public Edge (Zone 1) from the Private Factory (Zone 2).
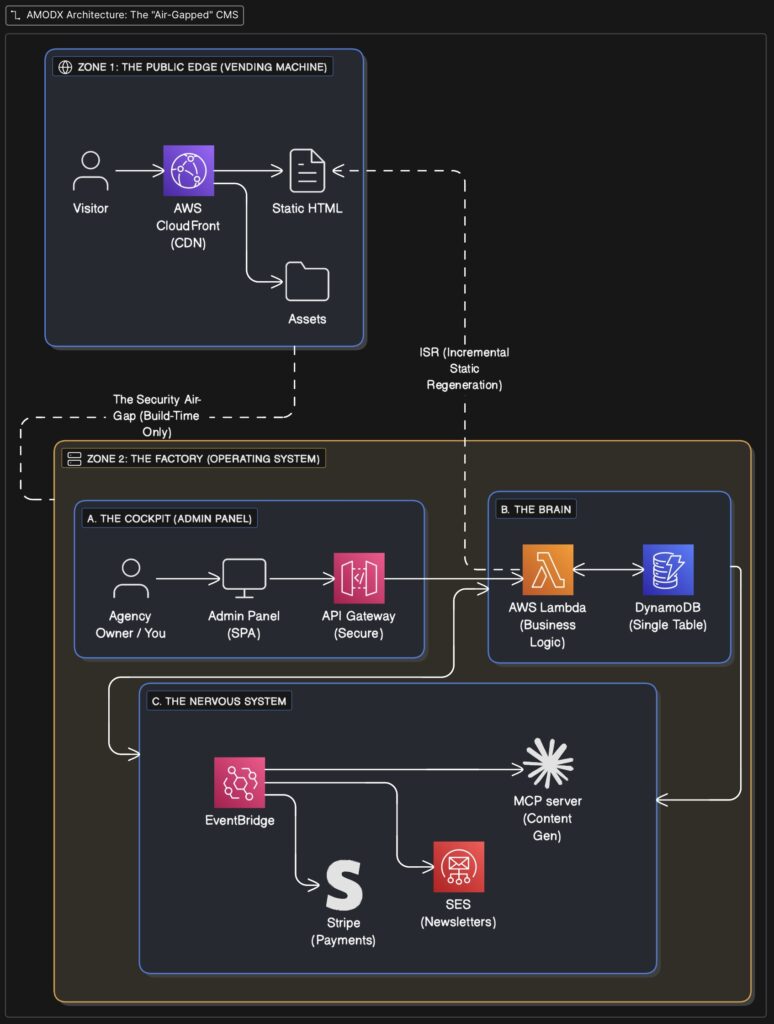
- The Vending Machine (Zone 1): The visitor interacts only with AWS CloudFront and S3. It is static. It loads in <100ms. It is unhackable because there is no database connection.
- The Factory (Zone 2): This is where I live. The Admin Panel, the Strategy Context, the AI Agents. It sits behind a secure API Gateway.
- The Bridge (ISR): When we publish, the Factory builds the page and pushes it across the gap to the Vending Machine.
The Factory goes to sleep when we aren’t working. Cost: $0.00.
Sprint Report: Systems Online
While the architecture is the map, the code is the territory. Here is what shipped this sprint:
- ✅ The Block Engine: We moved away from “Pages” to “Structured Blocks.” The Hero, Pricing Table, and Contact Formblocks are live and rendering via Next.js ISR.
- ✅ The Brain (MCP): I can now open Claude Desktop and say “Check the pricing strategy and update the landing page.” It reads from DynamoDB and updates the content without me clicking a button.
- ✅ The Media Library: Secure S3 uploads via Presigned URLs. No file size limits crashing the server.
- ✅ Deployment: You can take the code, follow instructions, and deploy your own agency on AWS and make as many sites as you want. Cloudfront for now.
Next Up: Identity & Commerce
The Core is solid. Now we build the application layer. The next sprint focuses on:
- The Two-Pool Auth Strategy: Strictly separating “Agency Admins” (Cognito) from “Site Visitors” (Public Pools). This enables comments, communities, and courses.
- Linking a Domain: Hook a site to an actual domain and test out the analytics integration.
- The Vault: Native Stripe integration for selling products and memberships.
The Foundry is hot. We are shipping.